Home
Results
Context
The accuracy of this kind of recommender tends to be very low. Although we recommended ten coupons for every user, many of them likely did not purchase a full ten during the test period. In addition, there are a very large number of possible coupons, often looking very similar across many attributes of our given data.
Algorithms used in Baseline Prediction
- A 3-Nearest Neighbors classifier was used to predict the popularity of coupons, as it had the best results with the training data, getting 37.91%popularity correct.
- The next best, a Naive Bayes classifier, got only 31.07% correct.
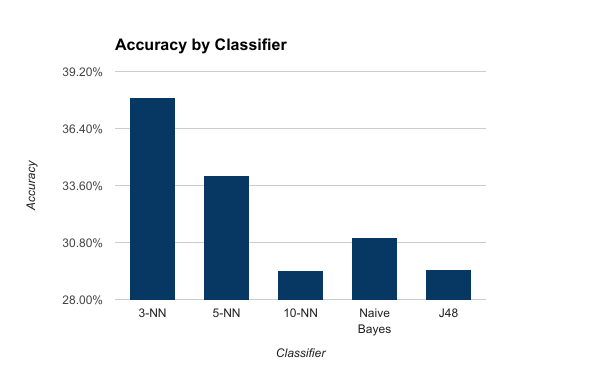
Figure 1. Coupon popularity accuracy on various classifiers
Final Results and Future Work
After building our model and recommending coupons,
-
Using Cosine Similarity
- Using only Cosine Similarity, the accuracy obtained was 0.78%
- Taking Coupon Viewed Logs into Consideration, the accuracy was 0.89%
- Using Pearson Correlation between Sparse Matrices, we got 1.095%
Since the Cosine Similarity got a much higher accuracy than our baseline, we were pleased with the results. It was helpful that we could see how the accuracies improved every time we included additional data or methods in our approach.
If we continued to work on this project, we would like to try some feature engineering on the available data. We would also like to be able to try out different algorithms such as Multi layered Neural Network, a Gradient Boosted Decision Tree etc. Unfortunately, since the dataset is so large, if we had added many more attributes to it the algorithms would have taken much longer to run. Most of the top scorers on Kaggle reported run times of between 24 hours to days, on very high end servers. This also allowed us less flexibility in trying out different approaches. Looking at all the challenges faced, we now know why this was a competition on Kaggle. But it was indeed an interesting challenge, one from which we gained a lot of knowledge